Projects

Water
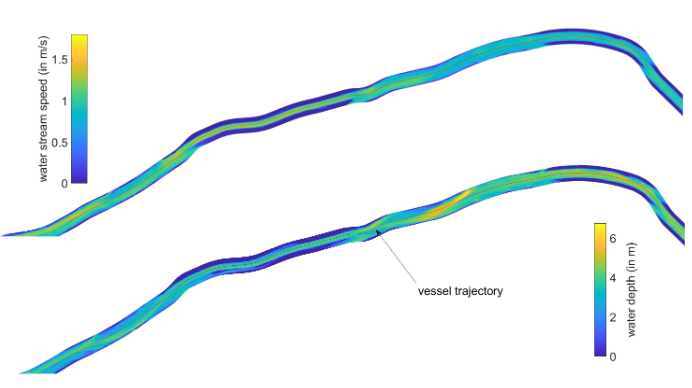
Navigating maritime traffic poses multifaceted challenges, including the intricate interplay of environmental factors like wind, waves, and currents, alongside the dynamic presence of other vessels with varying behaviors. These complexities demand precise control strategies that can adapt to real-world conditions, considering factors such as shallow water impacts and spatial restrictions imposed by waterway geometry. Within our research, we aim to address these challenges through modularized frameworks and advanced reinforcement learning techniques, facilitating realistic path planning and robust control of autonomous vessels in diverse maritime environments.
Ground
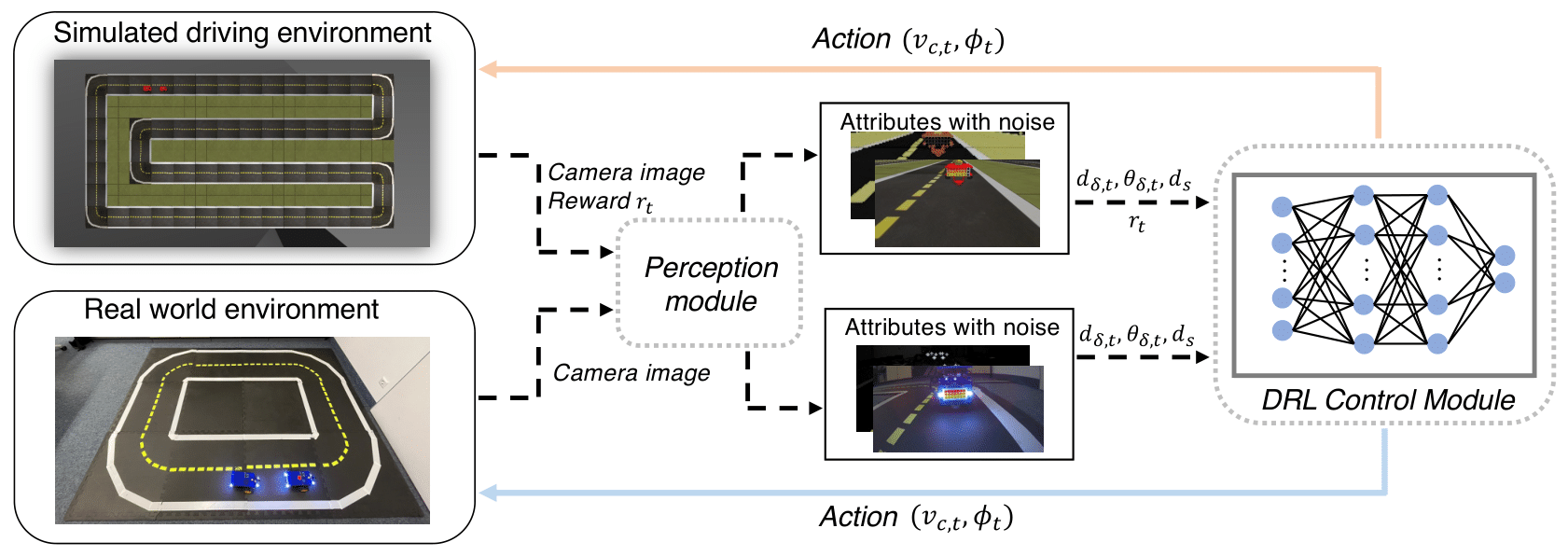
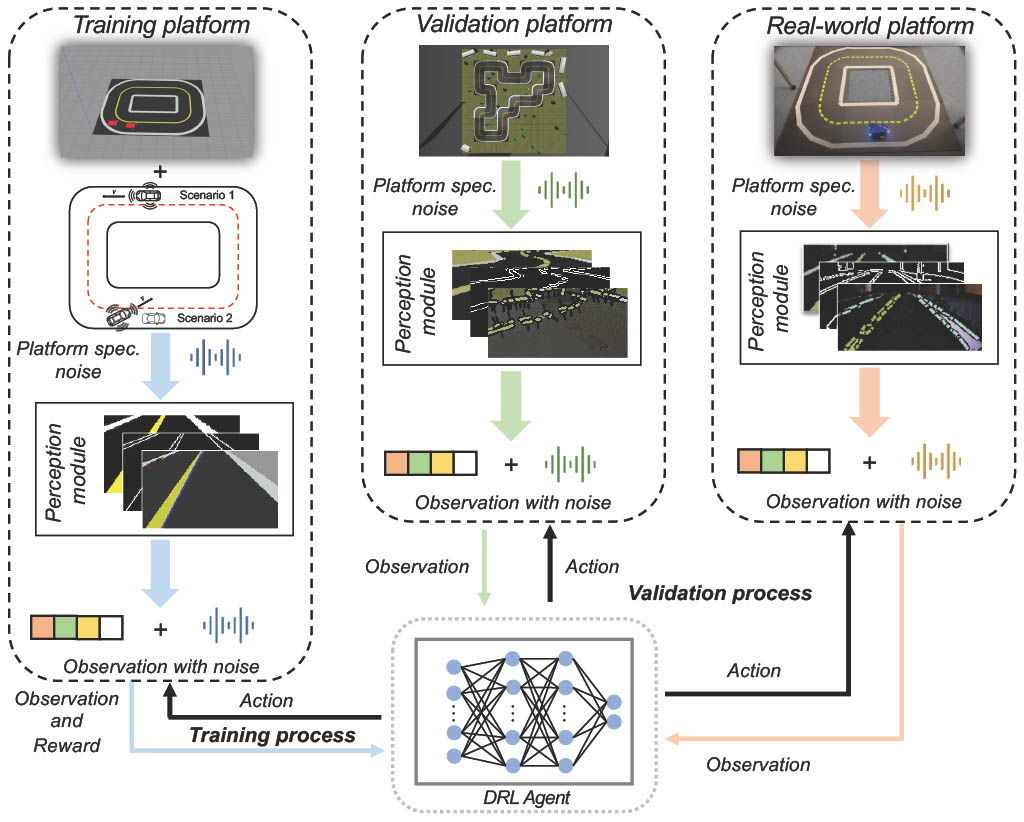
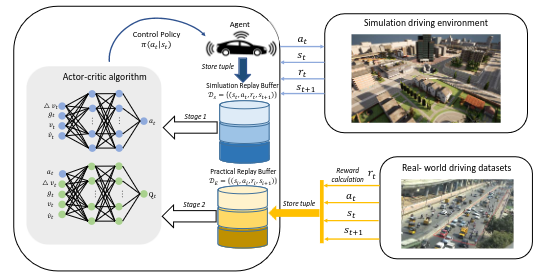
Addressing urban congestion and outdated infrastructure while improving traffic flow and reducing pollution is crucial. Implementing advanced traffic management systems equipped with AI algorithms can optimize flow and reduce congestion through dynamic route planning. We do our best to develop those AI algorithms. Among other tasks, to overcome the challenge of transferring trained autonomous vehicle agents from simulation to reality, we focus on separating agents into perception and control modules, enabling smoother integration into real-world environments. Similarly, by incorporating real-world driving datasets into training reinforcement learning agents, we aim to enhance their behavior and generalization capabilities, ultimately improving autonomous driving systems' performance on actual roads.

Air
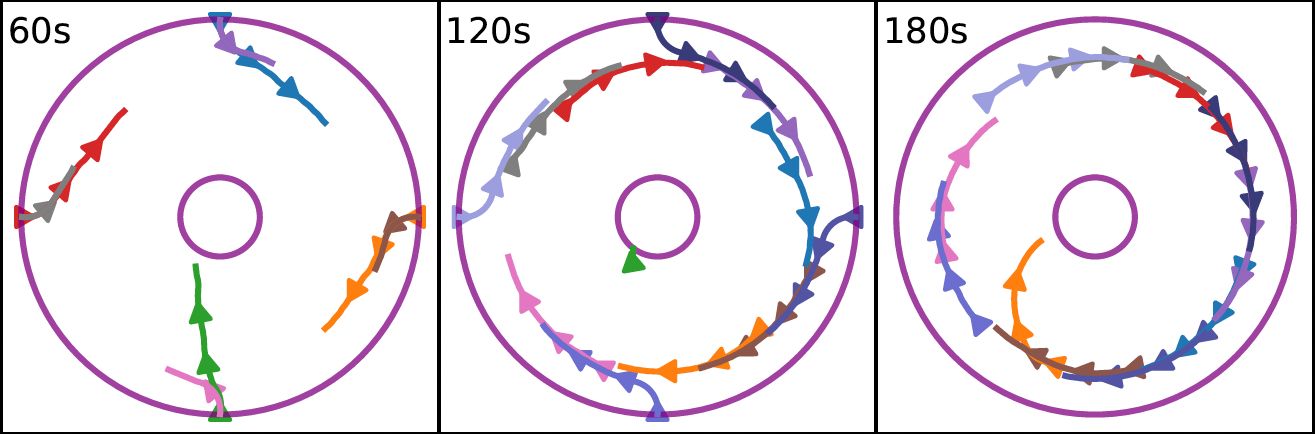
Urban air mobility presents unique challenges in managing eVTOL vehicles around vertiports, including congestion, safety, and unpredictable factors like weather and passenger demand. Among others, in our project, we address these complexities by proposing self-organized arrival systems using deep reinforcement learning. Treating each aircraft as an individual agent, we develop a shared policy for decentralized actions based on local information.
Methods
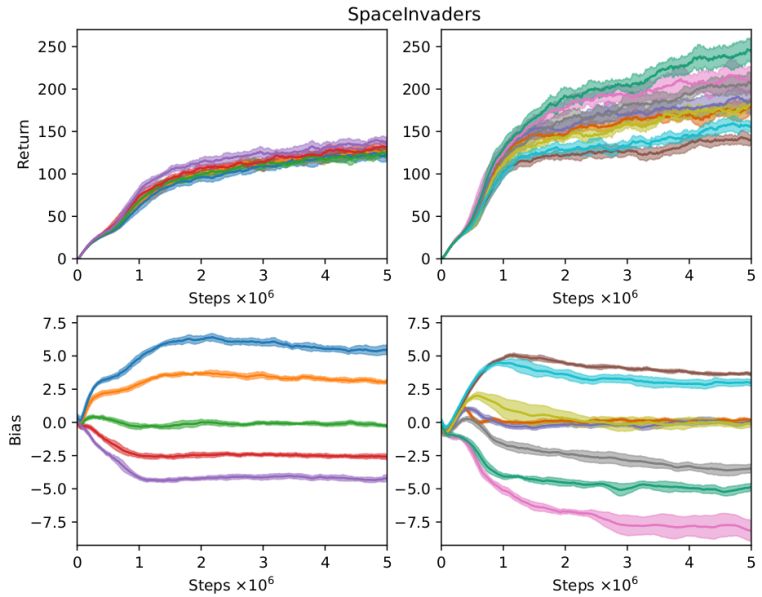
The continual development of new algorithms and models is imperative to tackle practical challenges with reinforcement learning. Even established methods like Q-Learning encounter limitations, particularly regarding the maximization operator in target computation. Inherent in the Bellman optimality equation, this operator often inflates Q-values for state-action pairs, impacting subsequent updates. As part of our broader theoretical endeavors in reinforcement learning, we are currently developing a novel suite of estimators tailored to address the max-mu problem, seamlessly integrating them within the framework of deep neural network-based function approximations.
Software
RL Dresden Algorithm Suite [GitHub]
This suite implements several model-free off-policy deep reinforcement learning algorithms for discrete and continuous action spaces in PyTorch.
Mixed Traffic Web Simulators [mtreiber.de]
Fully operational, 2D, Javascript-based web simulator implementing the "Mixed Traffic flow Model" (MTM). This simulation is intended to demonstrate fully two-dimensional but directed traffic flow and visulalize 2D flow models.

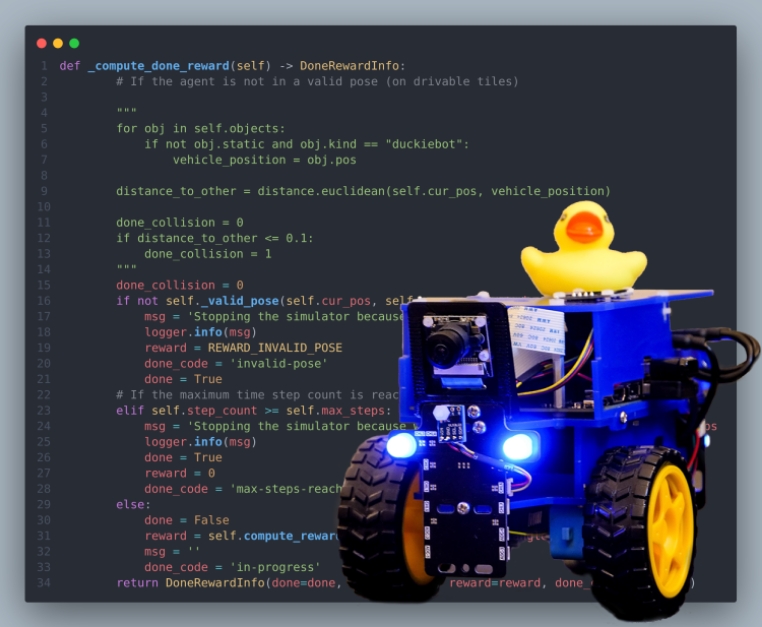
Sim2Real Transfer package with Duckiebot [GitHub]
This package includes the training and evaluation code under ROS platform for Sim2Real Transfer with Duckiebot for multiple autonomous driving behaviors.
Publications
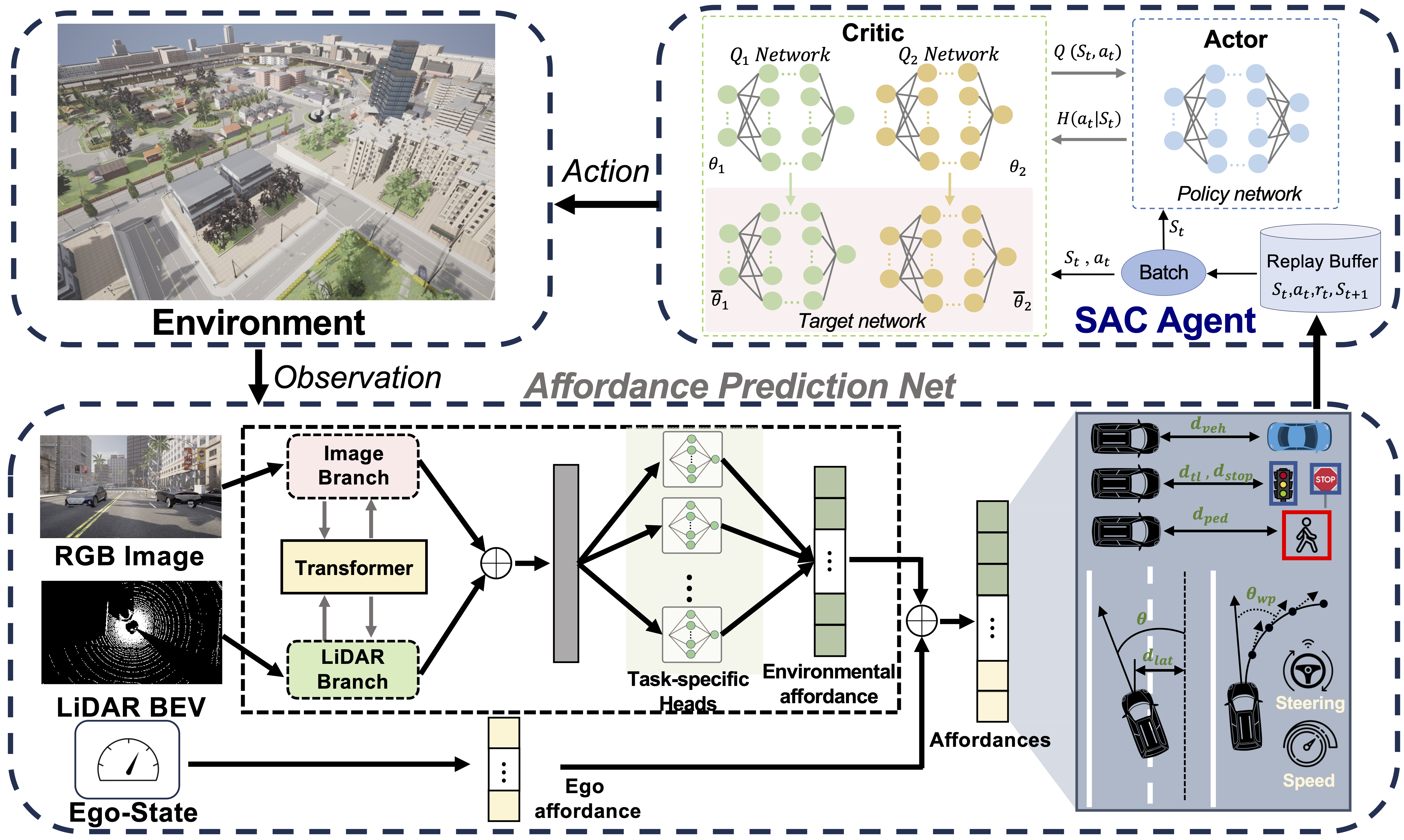
MTA-RL: Robust Urban Driving via Multi-modal Transformer-based 3D Affordances and Reinforcement Learning
Chen, G., Li, D., Zhong, W., Xie, B. Okhrin, O., IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2026).
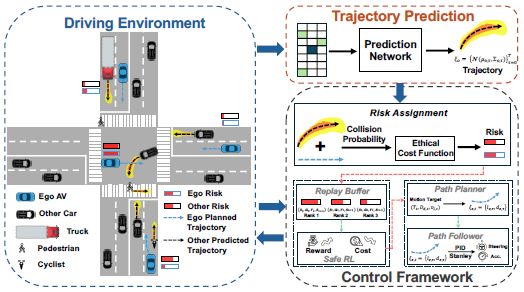
Ethics-Aware Safe Reinforcement Learning for Rare-Event Risk Control in Interactive Urban Driving
Li, D., & Okhrin, O. (2026). IEEE Transactions on Pattern Analysis and Machine Intelligence.
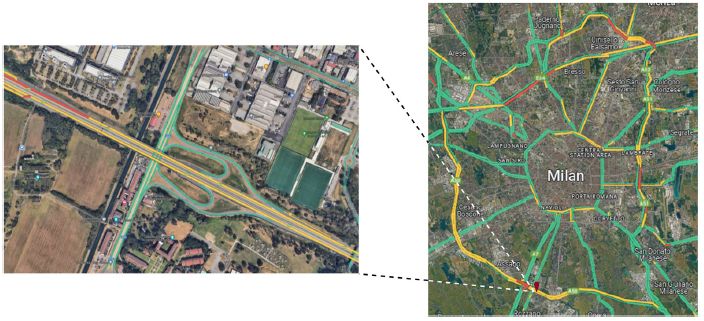
MiTra: A Drone-Based Trajectory Data for an All-Traffic-State Inclusive Freeway with Ramps
Chaudhari, A.A., Treiber, M., Okhrin, O. (2025). Scientific Data volume 12, Article number: 1174 (2025).
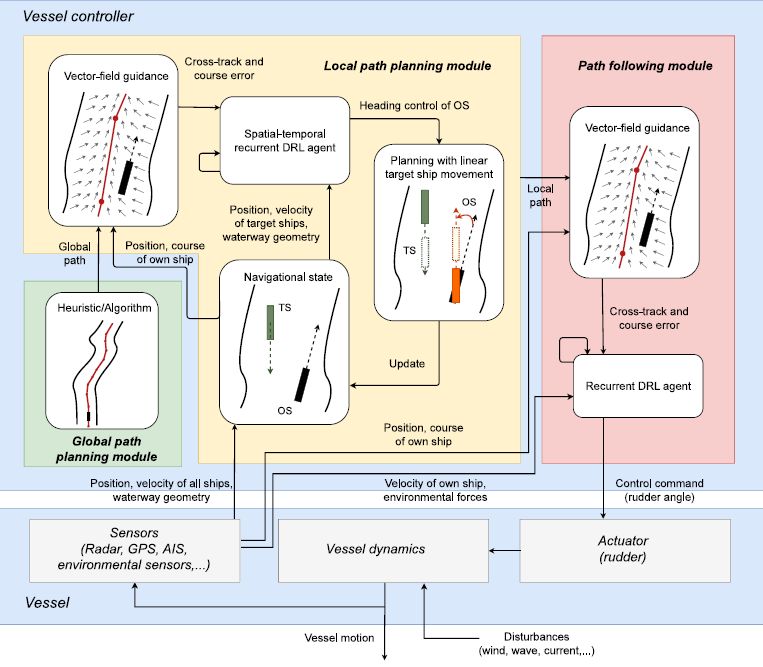
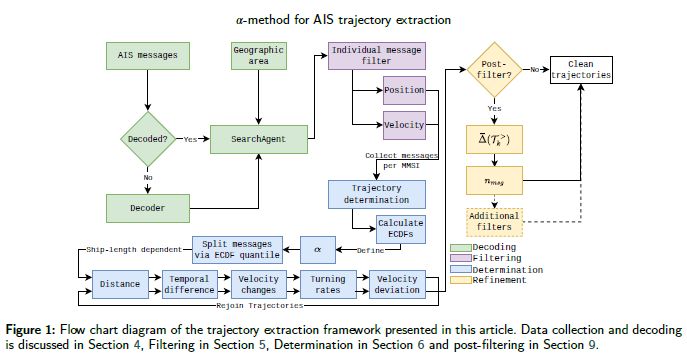
2-level reinforcement learning for ships on inland waterways: Path planning and following
Waltz, M., Paulig, N., Okhrin, O. (2025). Expert Systems with Applications, Volume 274, 126933.
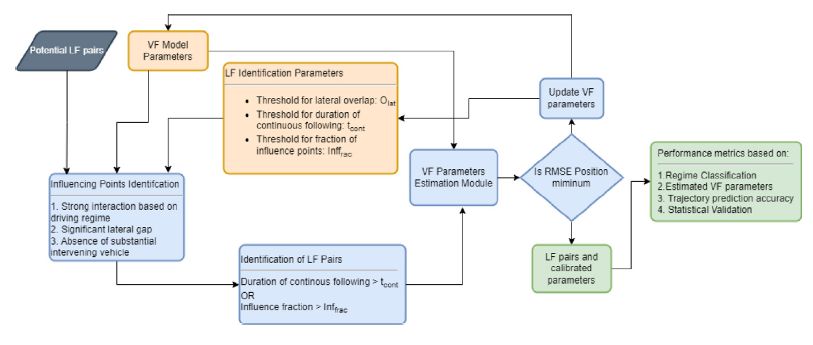
Leader–follower identification with vehicle-following calibration for non-lane-based traffic
Kulkarni, M. M., Chaudhari, A. A., Et al. (2025). Transportation Research Part C: Emerging Technologies 171, 104940.
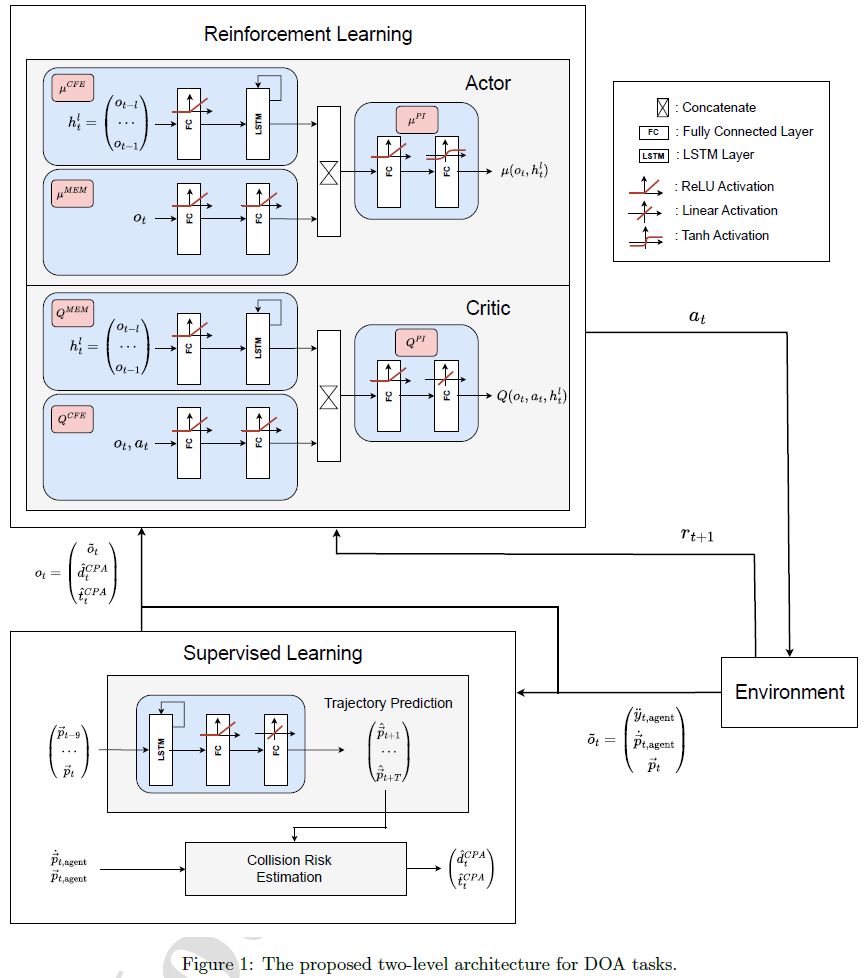
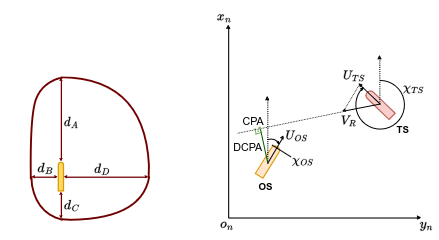
Two-step dynamic obstacle avoidance
Waltz, M., Okhrin, O., Hart, F. (2024). Knowledge-Based Systems, Volume 302, 112402.
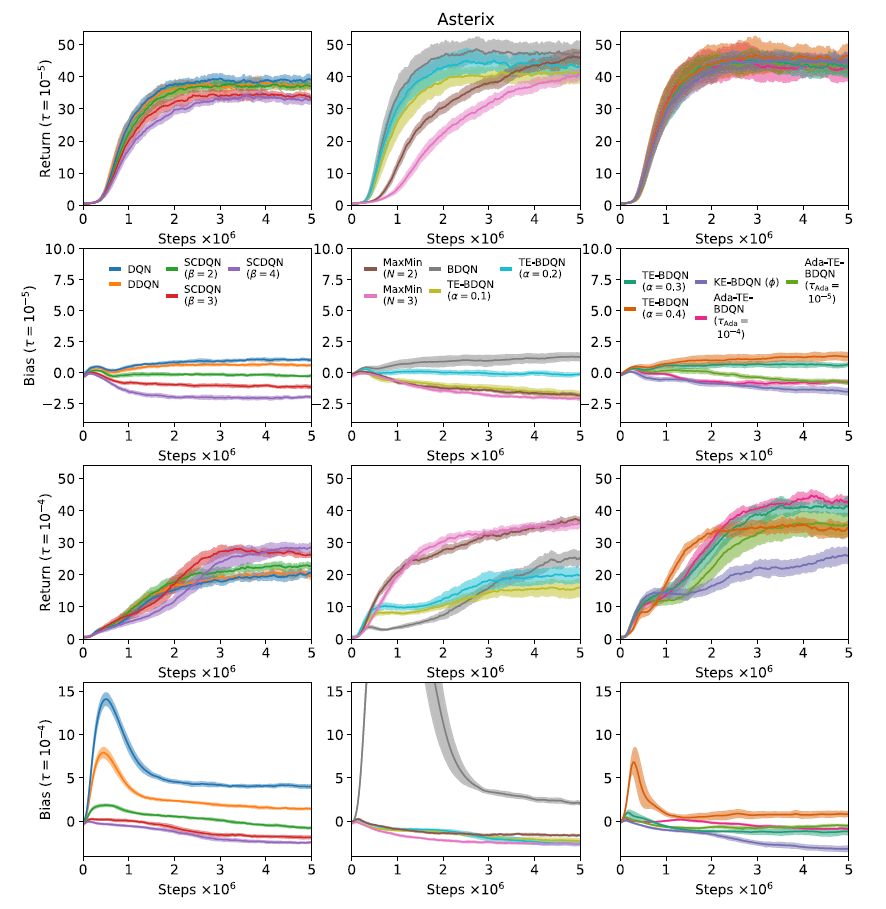
Addressing maximization bias in reinforcement learning with two-sample testing
Waltz, M., Okhrin, O. (2024). Artificial Intelligence 336, 104204
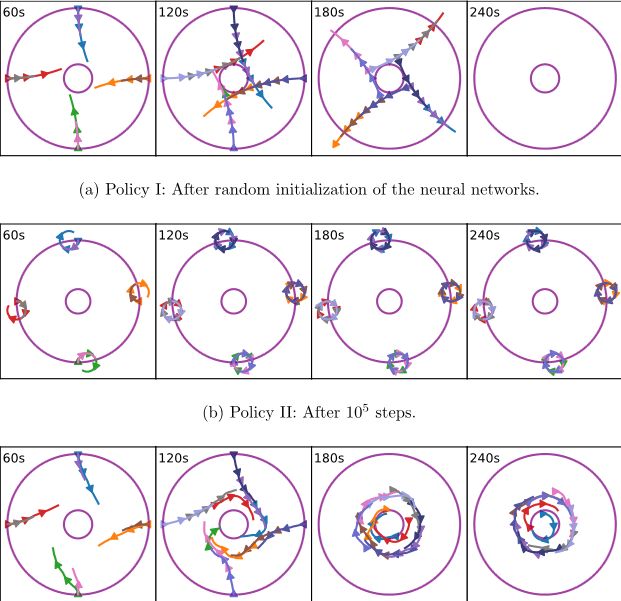
Self-organized free-flight arrival for urban air mobility
Waltz, M., Okhrin, O., Schultz, M. (2024). Transportation Research Part C: Emerging Technologies, Volume 167, 104806
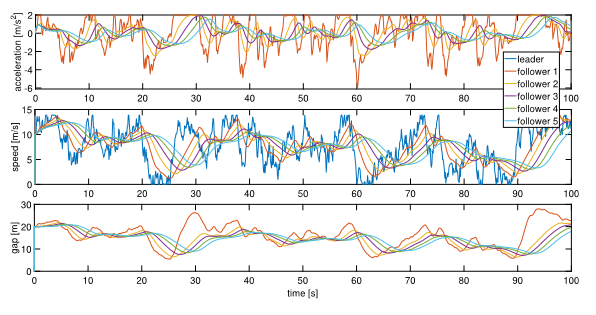
Towards robust car-following based on deep reinforcement learning
Hart, F., Okhrin, O., Treiber, M. (2024). Transportation Research Part C: Emerging Technologies, Volume 159, 104486
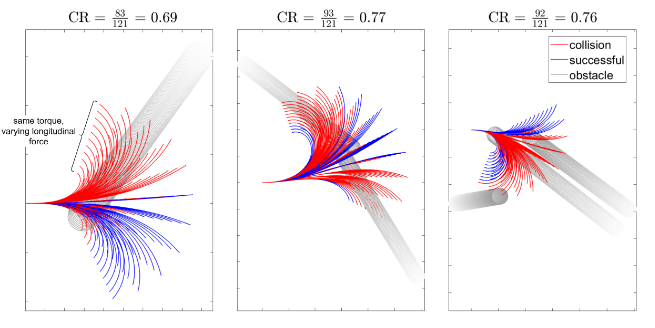
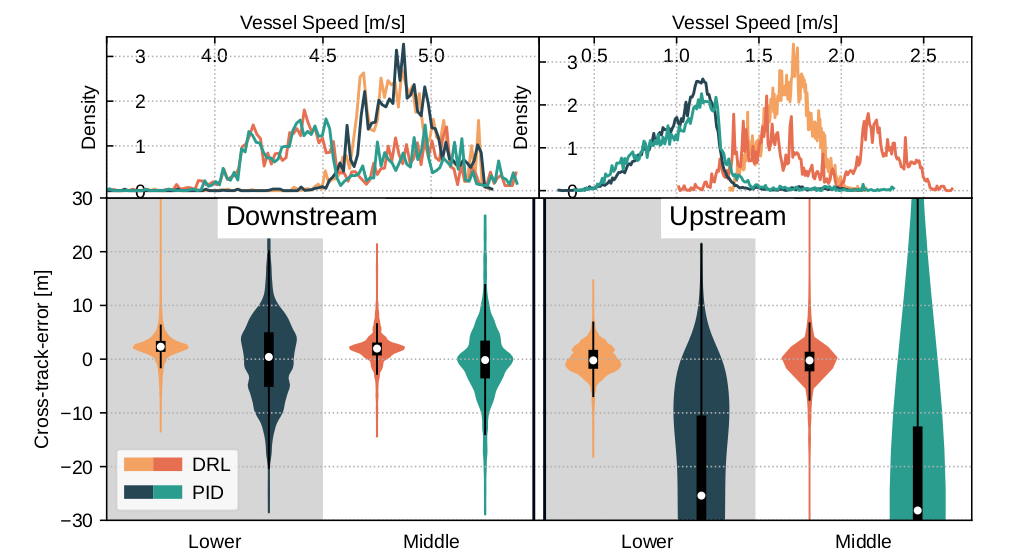
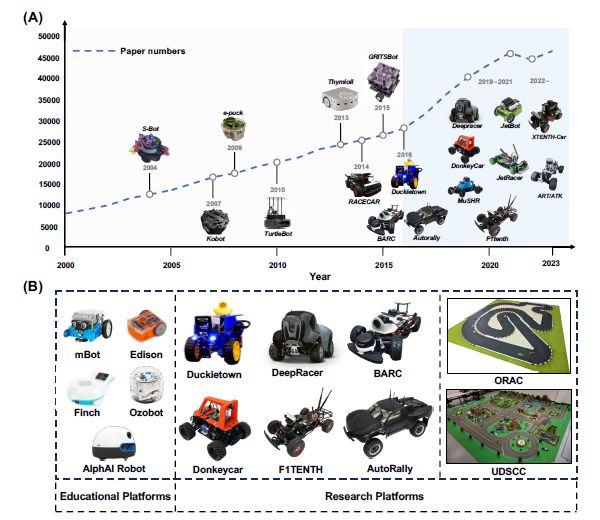
Student Works
Team
Prof. Dr. Ostap Okhrin
Ostap Okhrin is the professor for Statistics and Econometrics at the Department of Transportation at the TU Dresden. His expertise lies in mathematical statistics and data science with applications in transportation and economics.


Dr. Martin Treiber
Martin Treiber is a senior expert in traffic flow models including human and automated driving, bicycle, and pedestrian traffic. He also works in traffic data analysis and simulation (traffic-simulation.de, mtreiber.de/mixedTraffic).
Florian Friedrich
Florian Friedrich is a RL Group research associate.


Dianzhao Li
Dianzhao Li is a research assistant at RL-Dresden, focusing on the area of trajectory planning for autonomously driving vehicles with reinforcement learning algorithms. He now mixes the human driving datasets with RL in simulated environments to achieve better performance for the vehicles.
Paul Auerbach
Paul Auerbach is a research associate at the Barkhausen Institut and collaborates with RL-Dresden on the simulation and solving of traffic scenarios with the help of reinforcement learning. He aims to transfer the learned RL models to real world model cars.


Ali Abbas Kapadia
Ali Abbas Kapadia is joining the Reinforcement Learning (RL) Research Group as part of the AGiMo project, a DFG-funded initiative that focuses on developing data-driven and responsible mobility planning solutions for future transportation systems.
Saad Sagheer
Saad Sagheer is a Civil Engineer who is currently working as a research associate and collabrates with BAW (Bundesanstalt für Wasserbau). His main field of research is to conduct micro-traffic simulation of inland vessels in Rhine especially Middle Rhine with different water level conditions related to climate change.

Ankit Anil Chaudhari
Ankit Chaudhari is currently working on "Enhancing Traffic-Flow Understanding by Two-Dimensional Microscopic Models". His research interests are traffic flow modelling, traffic simulation, mixed traffic flow, machine learning and reinforcement learning.

Bingyu Wang
Ms. Bingyu Wang focuses on the transparency of computationally rational user models, with particular interest in making such models interpretable and theoretically grounded.
